Mungojerrie
Overview
Mungojerrie is a reinforcement learning tool primarily designed for testing reward schemes for omega-regular objectives, of which Linear Temporal Logic (LTL) is a special case. Mungojerrie contains multiple reinforcement learning algorithms and a probabilistic model checker. Reward schemes from the following papers have been implemented:
-
“Omega-Regular Objectives in Model-Free Reinforcement Learning”. TACAS 2019. Ernst Moritz Hahn, Mateo Perez, Sven Schewe, Fabio Somenzi, Ashutosh Trivedi, Dominik Wojtczak
-
“Good-for-MDPs Automata for Probabilistic Analysis and Reinforcement Learning”. TACAS 2020. Ernst Moritz Hahn, Mateo Perez, Sven Schewe, Fabio Somenzi, Ashutosh Trivedi, Dominik Wojtczak
-
“Model-Free Reinforcement Learning for Stochastic Parity Games”. CONCUR 2020. Ernst Moritz Hahn, Mateo Perez, Sven Schewe, Fabio Somenzi, Ashutosh Trivedi, Dominik Wojtczak
-
“Faithful and Effective Reward Schemes for Model-Free Reinforcement Learning of Omega-Regular Objectives”. ATVA 2020. Ernst Moritz Hahn, Mateo Perez, Sven Schewe, Fabio Somenzi, Ashutosh Trivedi, Dominik Wojtczak
-
"Model-Free Reinforcement Learning for Lexicographic Omega-Regular Objectives". To appear FM 2021. Ernst Moritz Hahn, Mateo Perez, Sven Schewe, Fabio Somenzi, Ashutosh Trivedi, Dominik Wojtczak
-
"Control Synthesis from Linear Temporal Logic Specifications using Model-Free Reinforcement Learning". ICRA 2020. Alper Kamil Bozkurt, Yu Wang, Michael M. Zavlanos, Miroslav Pajic
-
"A learning based approach to control synthesis of Markov decision processes for linear temporal logic specifications". CDC 2014. Dorsa Sadigh, Eric S. Kim, Samuel Coogan, S. Shankar Sastry, Sanjit A. Seshia. Note: This reward scheme may produce incorrect results. See Examples 1 and 2 in Section 3 of “Omega-Regular Objectives in Model-Free Reinforcement Learning”.
Mungojerrie also includes the capability to perform Q-learning on Branching Markov Decision Processes as presented in "Model-Free Reinforcement Learning for Branching Markov Decision Processes".
Mungojerrie reads Markov decision processes and Markov games described in the PRISM language, and automata written in the HOA format. Linking to the LTL translators epmc-mj, Owl, and SPOT is provided.
Benchmarks can be found at https://plv.colorado.edu/omega-regular-rl-benchmarks-2019/ and https://github.com/cuplv/parityRLBenchmarks. See the "examples" directory for a selection of PRISM and HOA files. "examples/catalog.txt" contains a description of the appropriate pairings for these files.
See Building and Installing for installation instructions.
Models
Markov decision processes and games are described in the PRISM language. Mungojerrie's parser accepts a subset of that language. The main restrictions are:
-
Only mdp, smg, and bdp model types are allowed. bdp is a custom extension described below.
-
Markov games are restricted to two players.
-
Multiple initial states (init ... endinit) are not implemented.
-
Process algebra operators (system ... endsystem) are not implemented.
-
Deadlock states (with no outgoing transitions) are not allowed.
-
Named actions must be deterministic.
Mungojerrie represents the model as an explicit graph. (That is, it does not use decision diagrams to represent sets of states and transitions.)
Branching Decision Processes
Mungojerrie also support Branching Markov Decision Processes (BMDPs, or simply BDPs) described in an extension of the PRISM language and supports only scalar rewards for BMDPs. BMDPs can be described in a minor extension of the PRISM language.The main modifications are:
-
It uses bdp keyword for the model type.
-
Branching transitions are implemented by introducing transitions to distinguished states controlled by the nature ("universal") player who then takes a transition to the various branches.
An example of the following BDP (branching transition are shown by double lines and probabilistic transitions are shown by a filled node) is shown below: 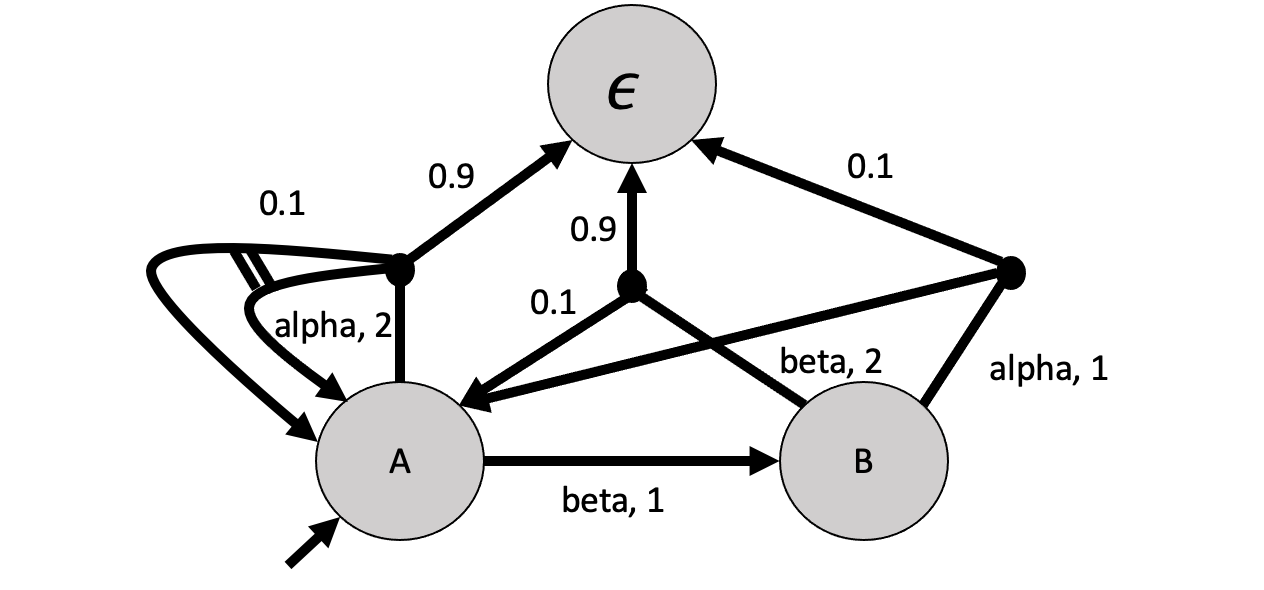
//Branching Decision Process
// p = 0.1
// q = 0.9
// r = 0.1
// entities = {A, B} init A
// A -(alpha, 2)-> p : A A + (1-p) : \epsilon
// A -(beta, 1)-> B
// B -(alpha, 1)-> q : A + (1-q) : \epsilon
// B -(beta, 2)-> r : A + (1-r) : \epsilon
bdp
const double p = 0.1;
const double q = 0.9;
const double r = 0.1;
label "final" = entity = 2; // extinction
module main
entity : [0..2] init 0;
nature : [0..1] init 0;
[alpha] entity=0 & nature = 0 -> p : (nature' = 1) + (1-p) : (entity' = 2);
[beta] entity=0 & nature = 0 -> (entity' = 1);
[alpha] entity=1 & nature = 0 -> q : (entity' = 0) + (1-q) : (entity' = 2);
[beta] entity=1 & nature = 0 -> r : (entity' = 0) + (1-p) : (entity' = 2);
[step] (entity = 2) & (nature = 0) -> (entity' = 2); // sink
[c1] nature = 1 -> (entity' = 0) & (nature' = 0);
[c2] nature = 1 -> (entity' = 0) & (nature' = 0);
endmodule
player Pentity
[alpha], [beta], [step]
endplayer
player Pnature
[c1], [c2]
endplayer
rewards
[alpha] entity=0 : 2;
[alpha] entity=1: 1;
[beta] entity=0 : 1;
[beta] entity=1: 2;
endrewards
For Branching Markov Decision Processes, Mungojerrie does not support omega-regular properties and it only allows computation and reinforcement learning for minimizing total expected cost objective for positive costs with Q-learning. Specifying rewards from the model can be done with --reward-type prism. We specify the costs with the PRISM reward syntax.
For more details, we refer to "Model-Free Reinforcement Learning for Branching Markov Decision Processes".
Properties
Mungojerrie synthesizes strategies to maximize the probability of satisfaction of an objective against the environment given by the PRISM model. The objective is specified by an ω-regular language. Mungojerrie maximizes the probability that a run of the Markov decision process or game produces a word in the language. Mungojerrie represents the objective as an ω-automaton. The user can provide an automaton directly, or, if support for external translators was compiled into Mungojerrie, as a Linear Temporal Logic (LTL) formula.
Mungojerrie reads automata in HOA format. The automata must have labels and acceptance conditions on the transitions (not on the states). The acceptance conditions supported by Mungojerrie are reducible to parity acceptance conditons without altering the transition structure of the automaton; besides (colored) parity conditions, Buchi, co-Buchi, Streett 1, and Rabin 1 conditions are supported. (A Streett 1 condition consists of one Streett pair; likewise for Rabin 1.) Four types of parity conditions are supported (max odd, max even, min odd, and min even). Mungojerrie converts all supported acceptance conditions to max odd parity. Hence, the output of the hoa-automaton option is always in that format. Generalized acceptance conditions are not supported in version 1.0. Nondeterministic automata may have "epsilon transitions," that is, transitions that consume no input. The atomic proposition name "epsilon" is reserved for that purpose. If a label depends on "epsilon" it must be "epsilon." Said otherwise, Boolean combinations including epsilon and other atomic propositions are not allowed.
Deterministic automata are needed to specify objectives for stochastic games. For Markov decision processes, the automata only have to be "Good for MDPs" (GFM). That is, they can have a limited form of nondeterminism. It is the user's responsibility to make sure that the automata are GFM. If Mungojerrie has been configured to use an LTL translator, that translator's algorithm may guarantee that the automaton is GFM. This is the case of the slim, semideterministic, and limit-deterministic automata produced by epmc-mj and owl.
Multiple properties can be specified simultaneously for use with lexicographic ω-regular objectives.
Examples
The files used in these examples can be found in "examples" under the source directory.
Forgiveness
To start, let's read in "forgiveness.prism" and output the MDP in DOT format for visualization. We can then run dot on the output to produce a pdf.
$ ./mungojerrie forgiveness.prism --dot-model forgiveness.dot
Input File is forgiveness.prism
@ 0.00507542 s: the environment has 16 nodes, 10 of which are decision nodes.
@ 0.00576797 s: end
$ dot -Tpdf forgiveness.dot -o forgiveness.pdf
Now, let's include a property for model checking. We will use epmc-mj and SPOT to create a slim automaton for "(FG x) | (GF y)". The maximum probability of satisfaction of the property on this example is 1.
$ ./mungojerrie forgiveness.prism -L "(FG x) | (GF y)" -a slim -m
Input File is forgiveness.prism
@ 0.00519455 s: the environment has 16 nodes, 10 of which are decision nodes.
@ 0.680529 s: the NBA has 9 states (1 trap).
@ 0.69437 s: the product has 48 nodes, 33 of which are decision nodes.
@ 0.694579 s: 2 WECs computed.
@ 0.69473 s: reachability completed.
@ 0.694741 s: probability of satisfaction: 1
@ 0.695811 s: end
Now we will learn a policy with Q-learning. We will leave the reward scheme and all hyperparameters at their default value. The pseudo-random seed will be fixed at 1 for reproducibility. Include "--learn-stats" for extra verbosity.
$ ./mungojerrie forgiveness.prism -L "(FG x) | (GF y)" -a slim --learn Q --seed 1 --reward-type default-type
Input File is forgiveness.prism
@ 0.00504934 s: the environment has 16 nodes, 10 of which are decision nodes.
@ 0.703496 s: the NBA has 9 states (1 trap).
--------QLearning--------
@ 3.1757 s: learning complete.
Probability for tol 0.01 is: 1
@ 3.17656 s: end
The default number of episodes is 20k. Let's reduce this to 5k and save the Q-table to "table.txt".
$ ./mungojerrie forgiveness.prism -L "(FG x) | (GF y)" -a slim --learn Q --seed 1 --reward-type default-type --ep-number 5000 --save-q table
Input File is forgiveness.prism
@ 0.00496114 s: the environment has 16 nodes, 10 of which are decision nodes.
@ 0.680191 s: the NBA has 9 states (1 trap).
--------QLearning--------
@ 1.3122 s: learning complete.
Probability for tol 0.01 is: 0.5
@ 1.3132 s: end
This wasn't enough training for our example. However, we can load the Q-table we saved and run an additional 5k episodes.
$ ./mungojerrie forgiveness.prism -L "(FG x) | (GF y)" -a slim --learn Q --seed 1 --reward-type default-type --ep-number 5000 --load-q table
Input File is forgiveness.prism
@ 0.00505809 s: the environment has 16 nodes, 10 of which are decision nodes.
@ 0.70742 s: the NBA has 9 states (1 trap).
--------QLearning--------
@ 1.32518 s: learning complete.
Probability for tol 0.01 is: 1
@ 1.32597 s: end
On this example, can we train with fewer episodes? Let's change our automaton to the handcrafted automaton specified in "forgiveness.hoa".
$ ./mungojerrie forgiveness.prism -p forgiveness.hoa --learn Q --seed 1 --reward-type default-type --ep-number 700
Input File is forgiveness.prism
@ 0.00515613 s: the environment has 16 nodes, 10 of which are decision nodes.
@ 0.0102494 s: the NBA has 3 states (0 traps).
--------QLearning--------
@ 0.0903915 s: learning complete.
Probability for tol 0.01 is: 1
@ 0.0909638 s: end
Output
Dot Output
Mungojerrie uses GraphViz's dot language to output models (either MDPs or Stochastic games), automata, products of models and automata, and the Markov chains that result from imposing the computed strategies in the products.
In the automata, each state, drawn as an ellipse, is labeled with its number. Each transitions is annotated with its label and its priority according to the max-odd scheme.
In MDPs, boxes are decision states and circles are probabilistic choice states. A decision state is annotated with the state name and the atomic propositions that are true in that state. For stochastic games, the maximizer's decision nodes are shown as boxes, while the minimizer's decision nodes are shaped as houses. For products and Markov chains, each state shows both the state of the MDP or game and the state of the automaton. Each transition is labelled with either an action or a probability–depending on the source state–and with the transition's priority.
Strategy Output
Mungojerrie can output the strategy computed by the model checker (see --save-mc-strategy) or from the learner (see --save-learner-strategy). The strategy output is a CSV file with delimiter ", " (comma space) for readability. Each CSV file starts with a header with the name of each column. The columns, in the order they appear, are:
- "State": The name of the state. The format is "[model state], [automaton state], [priority tracker state]". The model state is a concatenation of all the PRISM variables followed immediately by their value. The priority tracker state is only printed for the learner strategy, and will always be 0 unless the reward type is
pri-tracker.
- "Player": The player controlling that state.
- "Action"/"Action(s)": The action or actions the strategy selects in that state. The format is "[model action name]+[automaton next state]". The automaton next state may not be printed if the transition in the automaton is unambiguous. Epsilon actions in the automaton are printed as " epsilon[automaton next state]" (the leading space is intentional). If multiple actions are considered equal by the strategy in a particular state, they are concatenated with " & ".
Strategies from the model checker are pure. However, the learner may produce mixed strategies (see --tolerance).
Usage
./mungojerrie <Input File> [OPTIONS]
Example usage:
./mungojerrie -p test.hoa test.prism --learn Q
If a property is specified, Mungojerrie will form the synchronous product with the automaton. If model checking is enabled, Mungojerrie will compute the optimal probability of satisfaction of the property on this product. If learning is enabled, Mungojerrie will first execute the learning algorithm before using the model checker to compute the probability of satisfaction of the property under the learned strategy.
General options:
-h [ --help ]
-V [ --version ]
- Print version information
-v [ --verbosity ] LEVEL (=1)
- Set verbosity level (0-4)
-D [ --define ] CONST=VAL
- Give (new) values to model constants
-p [ --parity ] FILE
--to-ldba
--to-dpa
-L [ --ltl ] formula
- Note: requires providing path(s) to LTL translator(s) during configuration.
- LTL formula in the syntax of the chosen translator
-f [ --ltl-file ] filename
- Note: requires providing path(s) to LTL translator(s) during configuration.
- LTL formula file
-a [ --automaton-type ] formula (=slim)
- Note: requires providing path(s) to LTL translator(s) during configuration.
- Target automaton type for LTL formula translation [ldba, dpa, slim, semidet]
Printing options:
--dot-model filename
- Output model in dot format to [filename]. Use - for output to cout.
--dot-automaton filename
- Output automaton in dot format to [filename]. Use - for output to cout.
--dot-product filename
- Output synchronous product between model and automaton in dot format to [filename]. Use - for output to cout.
--dot-mc filename
- Output Markov chain for strategy in dot format to [filename]. Use - for output to cout.
--dot-learn filename
- Output learned pruned product graph in dot format to [filename]. Use - for output to cout.
--prism-model filename
- Output model in PRISM format to [filename]. Use - for output to cout.
--prism-product filename
- Output synchronous product between model and automaton in PRISM format to [filename]. Use - for output to cout.
--prism-mc filename
- Output Markov chain for the strategy in PRISM format to [filename]. Use - for output to cout.
--prism-learn filename
- Output learned pruned product graph in PRISM format to [filename]. Use - for output to cout.
--hoa-automaton filename
- Output automaton in HOA format to [filename]. Use - for output to cout.
Model checking options:
-m [ --model-check ]
--reach-with method (=iter)
- Note: [glop] requires linking with Google OR-Tools during configuration.
- Select method for probabilistic reachability [iter, glop]
--ssp-with method (=iter)
- Note: [glop, poly] requires linking with Google OR-Tools during configuration.
- Select method for stochastic shortest path [iter, glop, poly]
--epsilon arg (=1e-9)
- Tolerance for probability computations
--tran-epsilon arg (=1e-12)
- Tolerance for sum of transistion probabilities to be considered 1
--product-all
- If specified, the product is formed between all specified properties. Only the first property is model checked.
--save-mc-strategy filename
- Saves final pure strategy of model checker as CSV to [filename] for all visited states. Use - for output to cout.
--load-mc-strategy filename
- Loads pure strategy as CSV from [filename] which prunes the model to Markov chain before model checking.
- Matching is done via state names.
--save-all-mc-strategy
- If specified, the model checker strategy is output for all states, not just reachable states.
Learning options:
-l [ --learn ] arg (=none)
- Select learner [none, Q, DQ, SL]. Algorithms are Q-learning, Double Q-learning, and Sarsa(lambda).
--reward-type arg (=default-type)
- Select reward function [default-type, prism, zeta-reach, zeta-acc, zeta-discount, reward-on-acc, multi-discount, parity, pri-tracker, lexo]. See documentation for GymOptions::GymRewardTypes in Gym.hh for details.
--ep-number arg (=20000)
- Number of learning episodes
--ep-length arg (=30)
- Length of each learning episode
--zeta arg (=0.99)
- Probability that a learning agent will stay out of the sink at each accepting transition
--explore arg (=0.1)
- Probability that a random action is chosen during learning
--alpha arg (=0.1)
--discount arg (=0.99999)
- Discount for learning algorithms
--gammaB arg (=0.99)
- Second discount for multi-discount learning
--f-inv-scale arg (=0.01)
- Inverse of reward scaling factor for lexographic objective.
--linear-lr-decay arg (=-1 (off))
- Decays the learning rate linearly to specified value over the course of learning. Negative values turns decay off.
--linear-explore-decay arg (=-1 (off))
- Decays learning epsilon linearly to specified value over the course of learning. Negative values turns decay off.
--init-value arg (=0)
- Value initial Q-values are set to for learning
--lambda arg (=0.9)
- Value of lambda for Sarsa(lambda)
--replacing-trace
- Use replacing traces with Sarsa(lambda)
--tolerance arg (=[0.01])
- Actions with a Q-value within tolerance times the optimal Q-value are all merged into a mixed strategy during learning verification.
--pri-epsilon arg (=0.001)
- Probability used to advance priority tracker during learning verfication.
--learn-stats
- Prints statistics for the learning agent
--progress-bar
- Turns on progress bar for learning.
--save-q filename
- Saves Q-table(s) to [filename]. Format is Boost text archive.
--load-q filename
- Loads Q-table(s) from [filename]. May cause issues if loading Q-table(s) for a different model. Format is Boost text archive.
--checkpoint-freq arg (=0)
- Frequency to save Q-table(s) during training as a fraction of training length (values in [0,1]). 0 turns checkpointing off
--save-learner-strategy filename
- Saves final mixed strategy of learner as CSV file to [filename] for all visited states. Use - for output to cout.
--no-reset-on-acc
- Turns off resetting episode step when an accepting edge is passed for zeta-reach and zeta-acc
--terminal-update-on-time-limit
- Treat end of episodes that end due to episode limit as transitioning to zero value sink
--player-1-not-strategic
- Does not allow player 1 to change their strategy to the optimal counter-strategy to player 0 during the verification of the learned strategies.Instead, player 1 uses learned strategy.
--rand-init
- If specified, learner's initial state will be randomized for each episode.
--seed arg
- Pseudorandom number generator seed
Building and Installing
Mungojerrie includes cpphoafparser whose authors are gratefully acknowledged. Mungojerrie can optionally be linked against Google's OR Tools for linear programming support in the model checker.
Dependencies
For each tool you need to build Mungojerrie from source we list the versions that have been tested:
- A C/C++ compiler (gcc 7.3.0, 9.3.0, 10.2.0; clang 10.0.0, 11.0.0, 12.0.0)
- GNU make (4.1, 4.2.1, 4.3)
- flex (2.6.4)
- GNU Bison (3.0.4, 3.5.1, 3.7; versions older than 3.0.4 do not work)
- GNU autotools (automake 1.15.1, 1.16.2; autoconf 2.69)
- Boost Program Options and Serialization libraries (1.69, 1.71, 1.74)
- Google OR-tools (version for your operating system; optional)
- Doxygen (1.8.13, 1.8.17, 1.8.18; optional, to extract documentation from source code)
- dot (graphviz version 2.40.1, 2.43.0; optional)
- latex (texlive 2017, 2019; optional, for the documentation)
Building instructions
These instructions describe an "external build." Unpack the source code in a directory. We assume that this directory is called "mungojerrie." We also assume that the OR-tools are in directory /absolute/path/to/or-tools.
Create a build directory in the parent directory of directory mungojerrie. We assume that this directory is called "build-mungojerrie." Change your working directory to build-mungojerrie. Issue the following commands:
../mungojerrie/configure --enable-silent-rules --with-or-tools=/absolute/path/to/or-tools
make check
make html/index.html # to extract the documentation
This will produce a program called "mungojerrie" in the build directory and will run a sanity check.
Notes
--enable-silent-rules is optional- Run
../mungojerrie/configure --help to see the configuation options
External LTL Translators
Mungojerrie can use an external tool to translate an LTL formula into a good-for-games automaton in HOA format:
epmc-mj/SPOT produces slim and semideterministic automata- Owl's
ltl2ldba produces suitable limit-determinitic automata
SPOT produces parity automata
Mungojerrie's interaction with the LTL translators requires three additional Boost libraries:
- System
- Filesystem
- Process
A recent Java VM is also required for epmc-mj and Owl. (We tested with OpenJDK 11.)
- epmc-mj-v17.jar can be downloaded from here.
- SPOT can downloaded from here. We tested spot 2.9.5.
- Owl can be downloaded from here. We tested owl 20.06.
To let Mungojerrie connect to empc-mj/SPOT, configure with
--with-spot=<path to spot directory> --with-epmc-mj=<absolute path to epmc-mj directory>
To let Mungojerrie connect to Owl, configure with
--with-owl=<path to owl directory>
Installation
To install mungojerrie, type
make install
This copies the executable to the designated installation directory. The installation prefix defaults to /usr/local and can be changed with the --prefix option.
 1.8.17
1.8.17