Detection of Bugs in Android Apps via Dynamic Callback Analysis
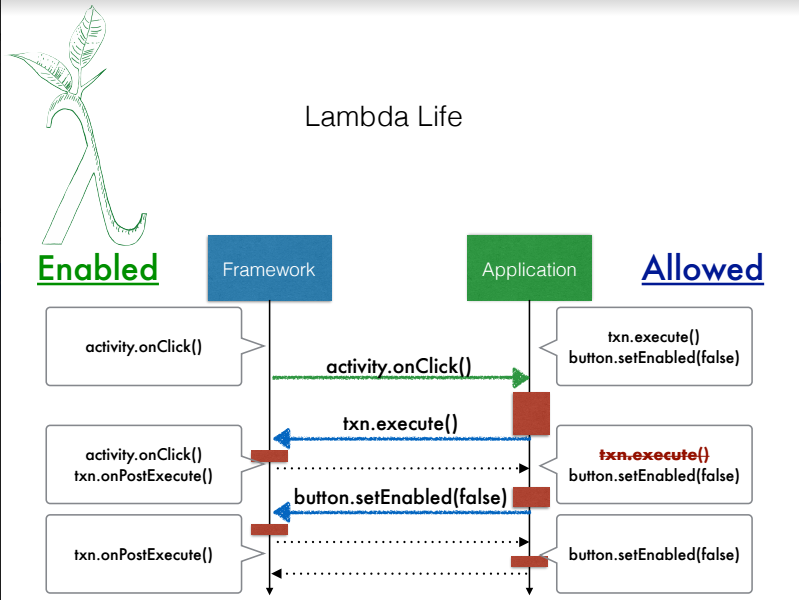
When implementing an Android application the developer will write a series of classes that implement methods called by the Android framework. These methods are used to communicate to the app what has happened to the phone, in response the app will communicate how it wants to respond by calling methods defined by the framework. This continuing dialog allows an application to successfully and responsively interact with its surroundings. However this dialog can be very foreign and come with a large number of constraints that make development difficult, especially when there is an ordering of callback invocations that the developer did not realize was possible. Our research aims to create automated methods of finding places where this ordering goes wrong in existing Android applications by monitoring the runtime behavior and searching for possible erroneous executions.